
You may be familiar with Binghamton Libraries’ long list of databases to help support research. But have you ever heard of its toolbox for doing text analysis? Text analysis is a computational method for “distant reading” or treating unorganized bodies of text as data and using computers to analyze them. Examples of this type of data could be a thousand movie reviews to the complete works of Shakespeare.
To simplify the data collection process and demystify the computational side, the library has subscriptions to several tools connected to databases that make text analysis accessible for the Binghamton community. Information about accessing these tools and more can be found in the Digital Scholarship Libguide. To help understand these tools, our two Undergraduate Digital Scholarship Associates, Sharon Reynolds and Susan Zheng, reviewed each of them. Neither had previous experience with text analysis before this review, but they were excited to try it out with library support.
Constellate
Constellate is a product of JSTOR and Ithaka that can supply basic visualizations with a chosen topic and then uniquely allows data exportation and subsequent access to a Jupyter Notebook environment, complete with many different tutorials. The notebooks allow users to understand the code behind text analysis without needing any programming skills.
Overall review:
This was Sharon’s only time with login issues, although it was fairly quickly resolved. Both reviewers found the initial dataset building and visualizations easy to use and access. However, since the data analysis is done in Jupyter notebooks, some barriers were created to immediately understand the analysis.
In their words:
“Creating a dataset was very manageable, and the process of finding documents was similar to using any standard database for research… Constellate does offer tutorials for those who are new to coding and want to learn how to analyze their datasets, but as a beginner to coding, I tried but did find it hard to follow the tutorial for analyzing word frequencies using Python.” – Susan
“I didn’t understand the coding side of it, but the part that I was able to do was very easy to navigate and understand.” – Sharon
Gale Digital Scholar Lab
Gale, a large purveyor of popular databases, has text analysis tools that break down the process into three steps: source selection, cleaning, and visualization. The operation is entirely point-and-click for the user, making text analysis accessible with minimal experience.
Overall review:
This was the simplest of the four sites for creating visualizations. Susan found a need to spend time pairing down the documents since the initial results were too big. Otherwise, every other part of the process was very simple and well-explained. Reviewers found this one to be the most user-friendly.
In their words:
“They had a list of suggested words to filter out, which was helpful, and I was able to go back and edit what I wanted to filter out as I ran into problems… The program easily made the visualizations for me, and they had videos explaining how the different data types work and what they mean.” – Sharon
“Gale may be better suited for research topics about literature, history, and political history. This was the first time I heard of and came across sentiment analysis. I was surprised that it was possible for a program to analyze the sentiments expressed in a written document.” – Susan
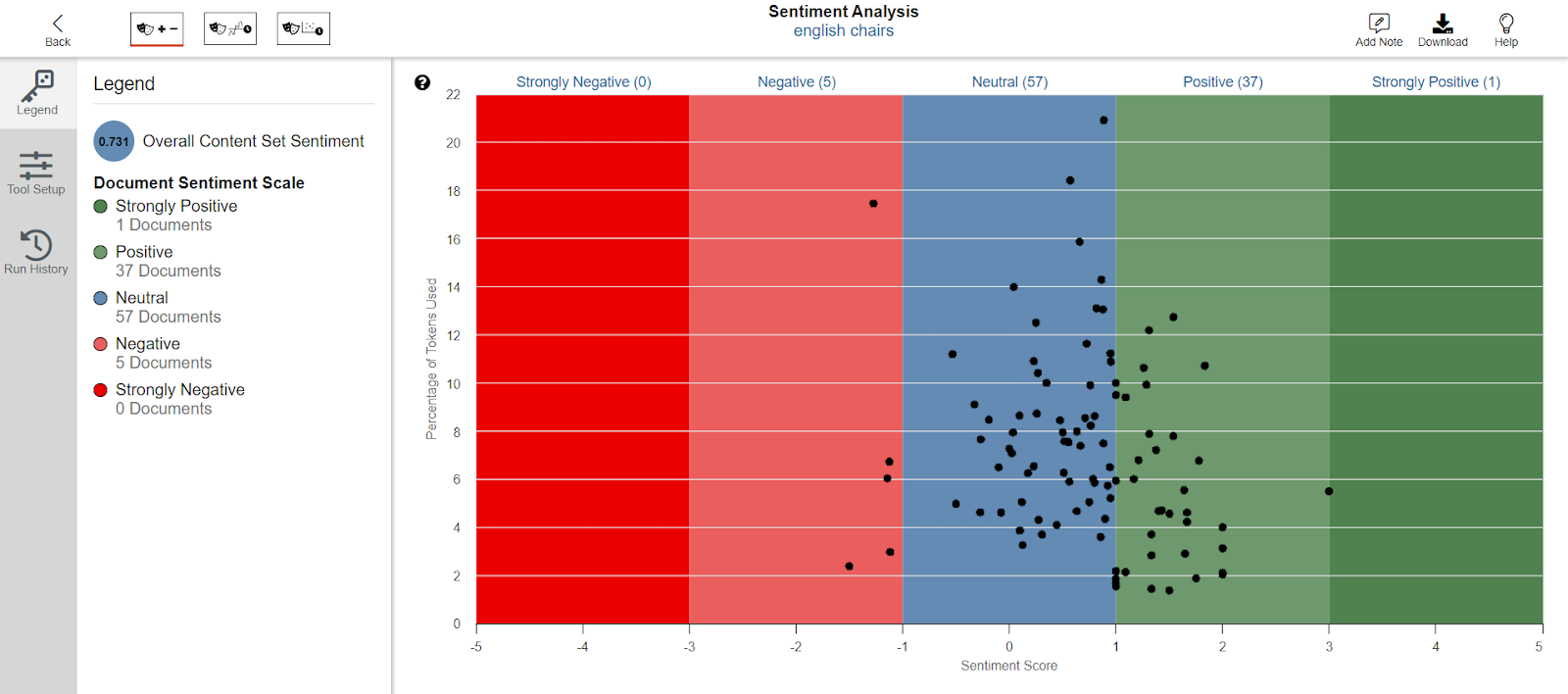
Hathi Trust Research Center
HathiTrust is a well-known collaborative repository for research libraries created by libraries in 2008. Three years later, they launched the HTRC to help aid in computational research on the resources in the repository. The tool has three main processes: visualizing, running algorithms and creating data capsules.

Overall review:
Both reviewers found the process the most confusing of the four since you collect your documents on another website and then bring them into HTRC for analysis. Some visualizations took 10+ minutes to render, but not all. Some steps are less intuitive if you have not done text analysis before, including exporting your work and adding stopwords.
In their words:
“I was a bit confused at the start but figured out that the collection had to be made from the HathiTrust.org website first… This was an extra step that had to be completed in comparison to other text analysis software” – Susan
“I didn’t realize that their database was more for serious documents like legal records, medical papers… Confusing at certain points but easy once you get the hang of it.” – Sharon
TDM Studio
TDM Studio, a product of Proquest, has a two-pronged approach. Users can create a point and click visualizations. Or they can use their programming skills in the workbench area to work with Proquest-owned data in a Juypter Notebook. The Jupyter environment includes some prepopulated code “manuals” to get started.
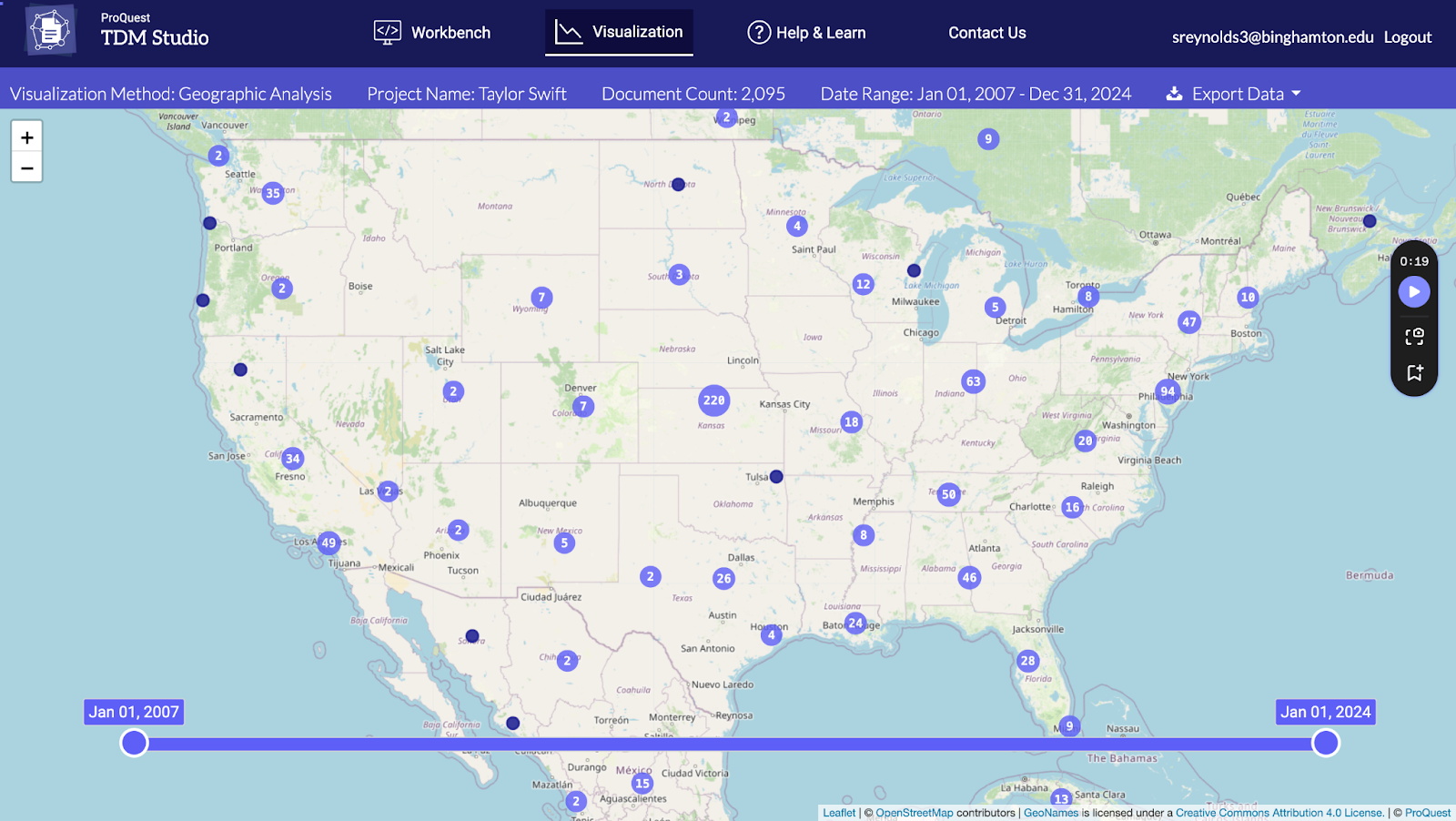
Overall review:
Both of the reviewers enjoyed the Geographical analysis, which they did find in the other tools. Unfortunately, there was no way to export the visualization besides screenshots. The visualization part of this tool also warns that the graphics can take a while to generate. One reviewer did not wait, and the other came back the next day, and they were ready.
In their words:
“It’s important to note that visualizations may not be generated immediately after dataset creation. Make sure you have ample time for the visualizations to be generated. – Susan
“I thought the geographic analysis was really cool! I liked how you can zoom around and change the date range at the bottom. You could also click on a cluster of locations and see the articles that were published there. I love that there are people writing their dissertations and theses about Taylor Swift all over the world.” – Sharon
Final Thoughts
Each tool has pros and cons. Choosing a tool, first and foremost, depends on the type of text you want to look at. Different databases specialize in different topics. After that, your choice will depend on how much time you want to invest in learning the process. Certain tools will be all point-and-click, which allows users to build and export quickly. Other tools focus on teaching you the skills and the code that go into the text analysis process.
For further inspiration on using these Text Analysis tools as part of your research, attend the Text Analysis Showcase from 1 – 3 p.m. Thursday, November 14 in the pilot Digital Scholarship Center (SL 209) to see what researchers on campus are doing. Contact the Digital Scholarship team (dscenter@binghamton.edu) for text analysis assistance.
Special thanks to the reviewers Sharon Reynolds and Susan Zheng.