
Written by Ruth Carpenter with Aidan Niebauer
Concordances, or books containing lists of words and the number of times an author used them, are useful tools for researchers trying to understand more about how authors use words. Concordances were traditionally done by hand and famous concordances were created for the Bible and complete works of Shakespeare to track, for example, how many times Shakespeare used the word ‘affliction’ (20) versus ‘madness’ (67). Now, this work can be automated with code and can go beyond counting words to producing complex statistical relationships between them. Using these broad methods of analysis on a collection of articles or books can help to quickly identify trends, inconsistencies or questions that may warrant deeper exploration. This past semester, the Digital Scholarship team worked with Aidan Niebauer, an undergraduate Linguistics major, through the Library Research Scholars program to conduct this kind of exploratory analysis.
The Library Research Scholars Program connects undergraduates interested in pursuing research opportunities to library faculty or professional staff to engage in Library related research. The Digital Scholarship team put out a call for a Library Research Scholar to work on a project using text analysis methodologies based on their scholarly interests. Essentially, Digital Scholarship would bring the tools and skills and teach the Research Scholar how to apply those skills to a collection of the texts that most interested them. For Niebauer, that meant exploring the history and trends of the terms ‘gender’ and ‘sexuality’ in the fields of sociolinguistics and linguistic anthropology.
“Digital text analysis is not a widely used research method in linguistics and anthropology, so applying it to my field was an entirely new experience,” said Niebauer. “In a field largely grounded in ethnographic, qualitative research, learning digital text analysis was challenging yet insightful.”
To keep the study manageable, the DS team and Niebauer selected one journal, Language and Society, to focus the analysis on. But, before Niebauer could jump into the collection, he needed to learn how to code. The DS team worked with Niebauer to lay out the basic coding skills that would help him interpret and adjust code for his project and a lesson plan that included basic Python and Pandas (a Python library that structures data into columns and rows for easy access). After spending some time to build his coding skills and confidence the DS team and Niebauer created a couple of mini-projects using smaller kinds of textual data, like the titles from articles or their keywords, to practice the entire text analysis process on.
As Niebauer says, “It wasn’t a walk in the park – learning to code was not easy and took a lot of practice and troubleshooting. We started with working on keywords and titles before fully branching into the full text, and this was a great introduction to digital text analysis that allowed me to become more familiar with the field as the project went on.”
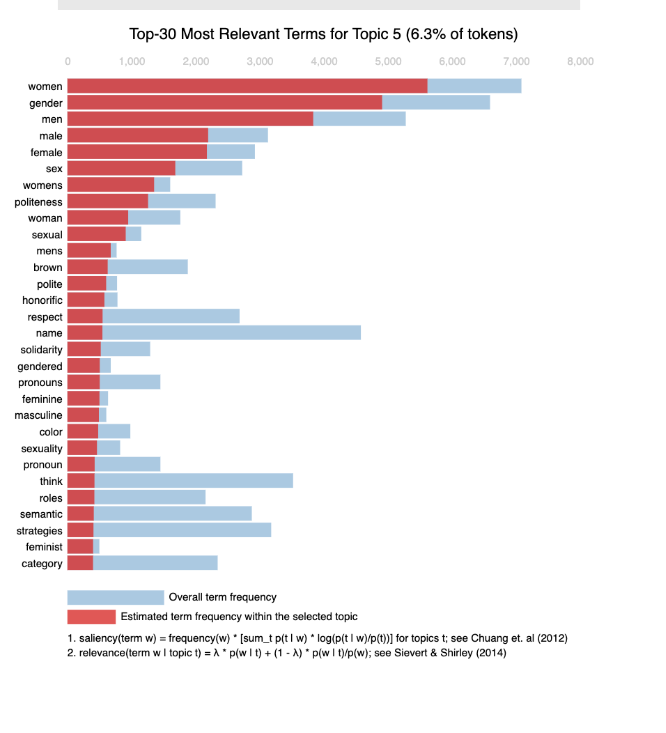
Once Niebauer was ready, the DS team and him delved into the full text excited to see what we would find. While the DS team and Niebauer considered a few different methodologies that would provide useful insight, the team landed on two main methods to focus on: LDA and TF-IDF analysis. Latent Dirichlet Allocation (LDA) is most useful for identifying major topics that emerge across a collection of texts. If you think about a set of movie synopsis, LDA would be helpful to automatically categorize those reviews into groups like ‘horror’, ‘romance’ or ‘horror romance’. For Niebauer’s research LDA would help him pull out what were important major topics or trends in the journal.
“In our LDA analysis (figure 1), the results showed that terms like ‘women’ and ‘feminine’ were more relevant to defining the field than ‘masculine’ and ‘men,’” said Niebauer. “I found this point very insightful when we empirically analyze the field. Historically, beginning research on language, gender and sexuality (LGS) was grounded in the dominance approach, arguing that men’s speech was inherently more powerful and reflected their dominant role in society.”
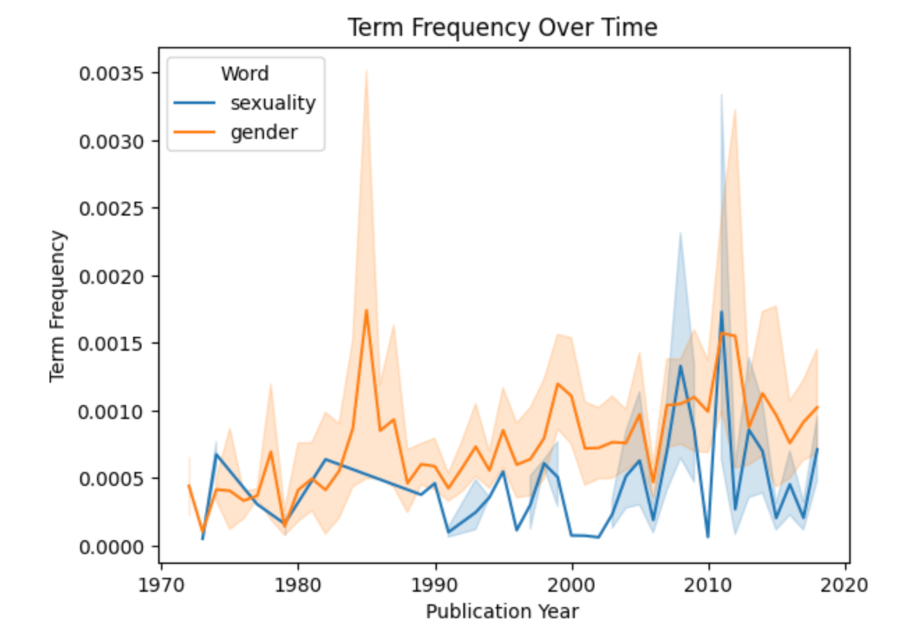
The other method, TF-IDF, was used to do word counts of the articles, but with a twist. Instead of just counting word occurrences, Term Frequency-Inverse Document Frequency (TF-IDF) calculates the relative frequency of a word in a document compared to its frequency across the entire collection of texts. In essence, a word that appears frequently across all the articles will have a lower TF-IDF score than a word that appears often in just one article but rarely in others. For the journal articles, TF-IDF analysis helped track the importance of terms over time
“Our TF-IDF analysis (figure 2) proved insightful as well, and reflected the trends of the field,” said Niebauer. “Studies that focused on sexuality were not prominent until the 2000s and 2010s. Until then, most scholarship focused on gender roles and viewing gender as a binary system. In recent years, we see more scholarship focusing on sexuality, such as Lal Zimman’s work on trans linguistics and the emergence of lavender linguistics.”
Teaching how to incorporate digital methods into the research process and showing the value of engaging in these types of methods is an important part of Digital Scholarship and the Libraries’ mission. Through the Library Research Scholars Program Niebauer’s work with the DS Team exemplifies the benefits of learning digital methods and applying them to disciplines that may not usually utilize them. Taking a project from beginning to end within a semester is challenging especially while building and learning new skills along the way. However, Niebauer persevered through being a beginner at Python and brought his expertise in his field to help guide the DS Team in turn when analysing the findings. Niebauer will present his poster during the Binghamton Research Days and hopes to continue using Python and text analysis for his future research.
“Using digital text analysis allowed me to view my field more broadly and analyze trends that are otherwise difficult to pin down over a large corpus of data,” Niebauer concluded. “I see great potential for digital text analysis use in corpus linguistics and anthropology.”
If you have a text analysis project you would like to explore with the Digital Scholarship team, reach out to us using our consultation form, or sign up for our newsletter to keep up to date about our text analysis workshops and learning opportunities.